Mem0
1. 基础概念
1.1 背景
Mem0(发音为 "mem-zero")是一款专为 AI 智能体设计的开源记忆管理系统,致力于解决 AI 交互过程中的"遗忘"难题。在传统应用中,用户在不同 AI 工具间切换时,常常会遇到上下文丢失、体验割裂等问题。Mem0 通过提供统一的记忆层,使智能体能够跨会话、跨应用持续保留用户偏好与历史交互信息,从而实现真正的个性化和持续学习体验。
Mem0 的核心愿景是成为用户的"记忆背包",让关键上下文信息能够在不同 AI 工具之间自由携带和共享。无论是客户支持、个人助手还是医疗咨询等场景,Mem0 都能为智能体赋予持久记忆和上下文感知能力,极大提升个性化交互体验和智能体的实用性。
根据 Mem0 最新的研究论文数据,Mem0 相较于 OpenAI Memory 方案,在准确率上提升了 26%,延迟降低了 91%,同时实现了 90% 的令牌消耗节省。这些显著的性能优势,使 Mem0 成为构建生产级 AI 智能体系统的理想选择。
Announcing our research paper: Mem0 achieves 26% higher accuracy than OpenAI Memory, 91% lower latency, and 90% token savings! Read the paper to learn how we're revolutionizing AI agent memory.'
1.2 核心概念
Mem0 的核心理念体现在以下几个方面:
- 记忆处理:利用大语言模型(LLM)自动从对话中提取关键信息,并将其结构化存储,确保上下文的完整性和可追溯性。
- 记忆管理:系统能够持续更新和维护存储的记忆内容,自动检测并解决信息冲突,保证记忆的准确性和一致性。
- 双重存储架构:创新性地结合了向量数据库(用于高效语义检索)和图数据库(用于实体关系追踪),实现了记忆的多维度管理。
- 智能检索系统:通过语义搜索与图查询相结合,能够基于记忆的重要性、时效性等多维度条件,精准检索出最相关的历史信息。
- 模型上下文协议(MCP):提供标准化的协议接口,支持不同 AI 应用间的记忆共享与互通,打破信息孤岛。
- 本地化处理:所有数据处理与存储均可在本地完成,极大保障了用户隐私和数据安全,用户对数据拥有完全控制权。
Mem0 支持多级记忆架构,包括:
- 用户级记忆:跨会话持久化保存用户偏好和历史行为
- 会话级记忆:记录当前交互的上下文信息
- 智能体级记忆:存储 AI 系统自身的知识和学习成果
2. 理论框架
2.1 记忆层架构
Mem0 的记忆层架构巧妙结合了大语言模型(LLM)与向量存储技术。LLM 负责从用户与智能体的对话中自动提取关键信息,而向量存储则将这些信息转化为高维向量,实现高效的语义检索。通过这种架构,AI 智能体能够将历史交互与当前上下文有机结合,生成更加相关和个性化的响应。
记忆层的核心工作流程包括:
- 信息提取:LLM 对对话内容进行深度分析,自动识别并提取出具有长期价值的关键信息点。
- 向量化:将提取出的信息通过嵌入模型转化为向量表示,便于后续的高效检索。
- 存储:将向量化后的记忆单元存储到向量数据库中,支持大规模、低延迟的语义检索。
- 检索:根据当前用户查询,系统在向量空间中检索出最相关的历史记忆。
- 整合:将检索到的记忆与当前对话上下文进行整合,辅助智能体生成更具针对性和连贯性的响应。
这种架构设计,使 Mem0 能够在保证高效率的同时,提供精准且可扩展的记忆检索服务。
2.2 Mem0 如何实现长期记忆
Mem0 的长期记忆系统基于以下核心机制:
- 采用向量嵌入技术,将语义信息高效存储与检索,确保记忆内容的可扩展性与相关性。
- 支持跨会话、跨应用维护用户特定的上下文,实现真正的"记忆不丢失"。
- 内置高效的检索机制,能够快速定位并返回与当前查询最相关的历史互动内容。
核心操作接口
Mem0 对外提供了两大核心 API 接口,便于开发者与记忆层进行交互:
- add:用于提取对话内容并将其存储为结构化记忆单元。
- search:根据用户查询,检索并返回最相关的历史记忆内容。
添加记忆流程
添加记忆的操作流程如下图所示:
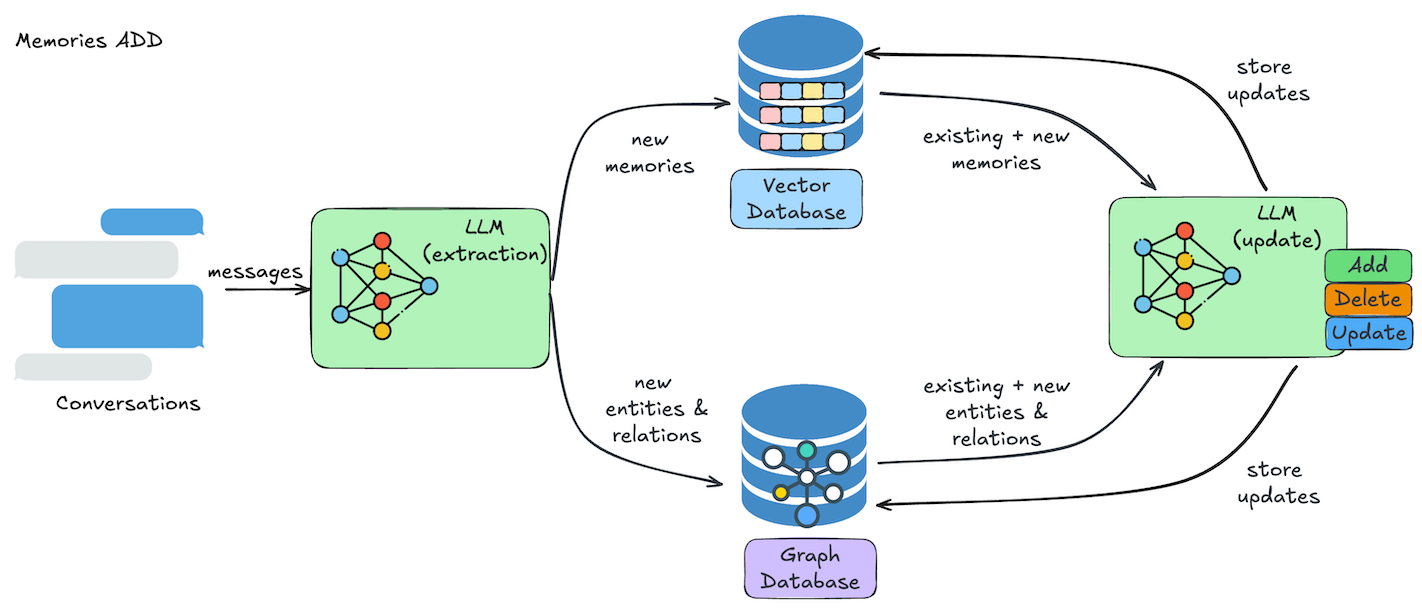
- 信息提取:LLM 从对话中自动提取出相关记忆,识别重要实体及其关系。
- 冲突解决:系统会将新提取的信息与现有记忆进行比对,自动识别并解决潜在的矛盾或重复内容,确保记忆的准确性。
- 记忆存储:最终的记忆内容会被存储到向量数据库中,同时相关的实体关系会同步到图数据库中。每次用户与智能体的互动,都会不断丰富和完善记忆库。
检索记忆流程
记忆检索的操作流程如下图所示:
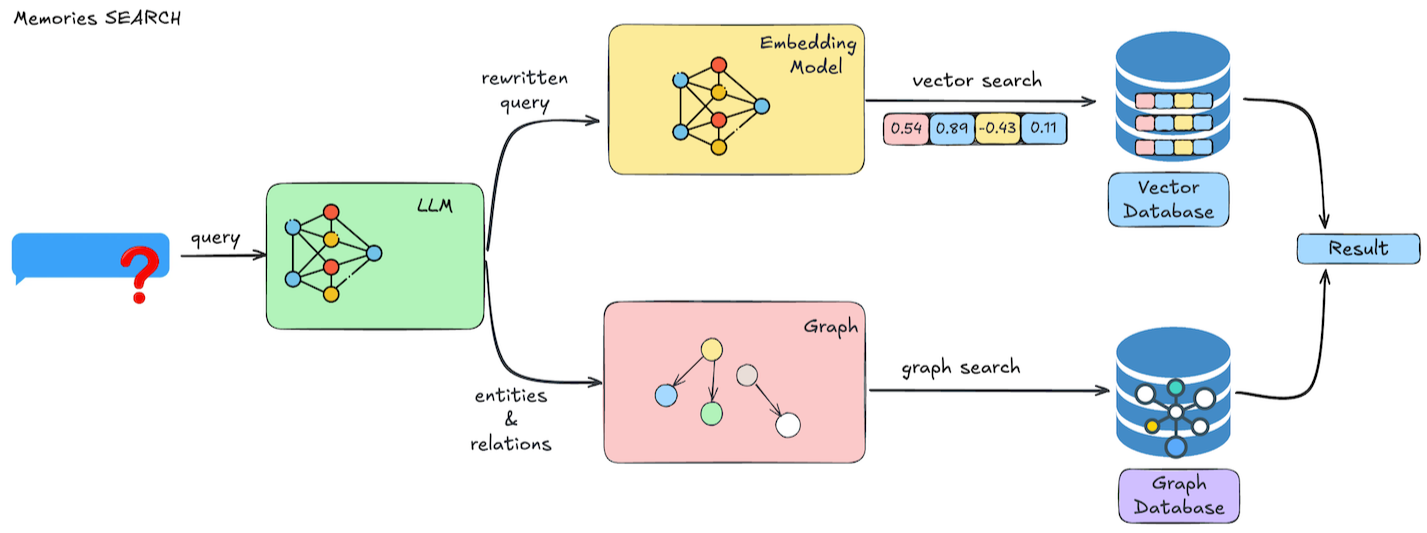
- 查询处理:LLM 首先对用户的查询进行理解和优化,系统自动生成针对性的检索过滤条件。
- 向量搜索:系统在向量数据库中执行高效的语义搜索,根据与查询的相关性对结果进行排序,并可按用户、代理、元数据等多维度进行过滤。
- 结果处理:系统将检索到的结果进行合并和排序,最终返回带有相关性分数、元数据和时间戳的记忆内容,供智能体进一步使用。
这种多步骤、语义驱动的检索方式,确保了无论是查找特定信息还是探索相关概念,Mem0 都能提供高质量的记忆检索体验。
本小节内容来源于 mem0.ai : Memory Operations
2.3 Mem0 图记忆
Mem0 现已支持图形记忆(Graph Memory),通过引入图数据库,用户可以创建和利用信息片段之间的复杂关系,实现更细致入微且具备情境感知的响应。这种集成让用户能够同时发挥基于向量和基于图结构的优势,提升信息检索的准确性和全面性。
示例用法
以下示例展示了如何使用 Mem0 的图形操作:
- 首先,为名为 Alice 的用户添加一些记忆。
- 随着记忆的不断添加,图结构会自动演化,实体和关系被自动提取和连接。
- 用户可以直观地看到记忆网络的变化。
添加记忆
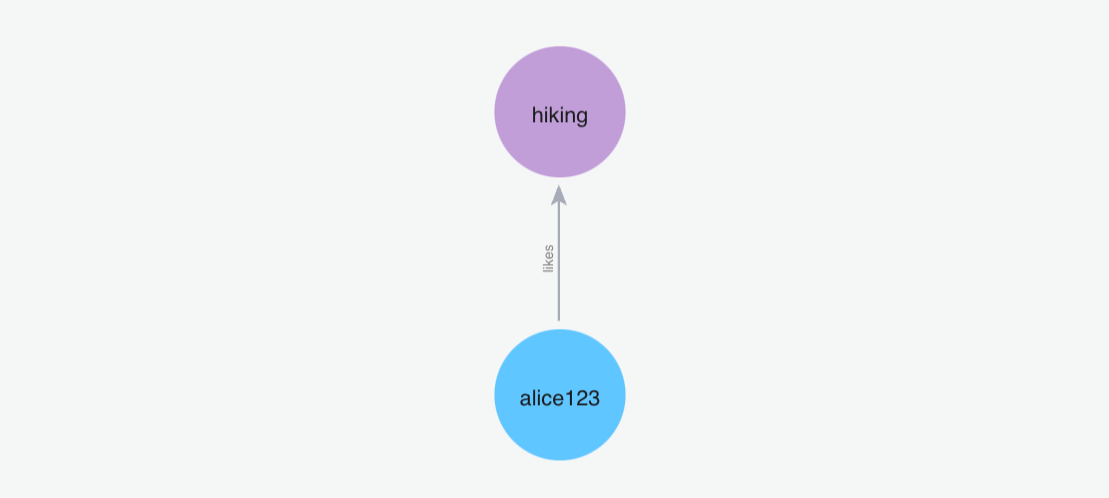
(1)添加记忆"我喜欢去远足"
Python 代码: m.add("I like going to hikes", user_id="alice123")
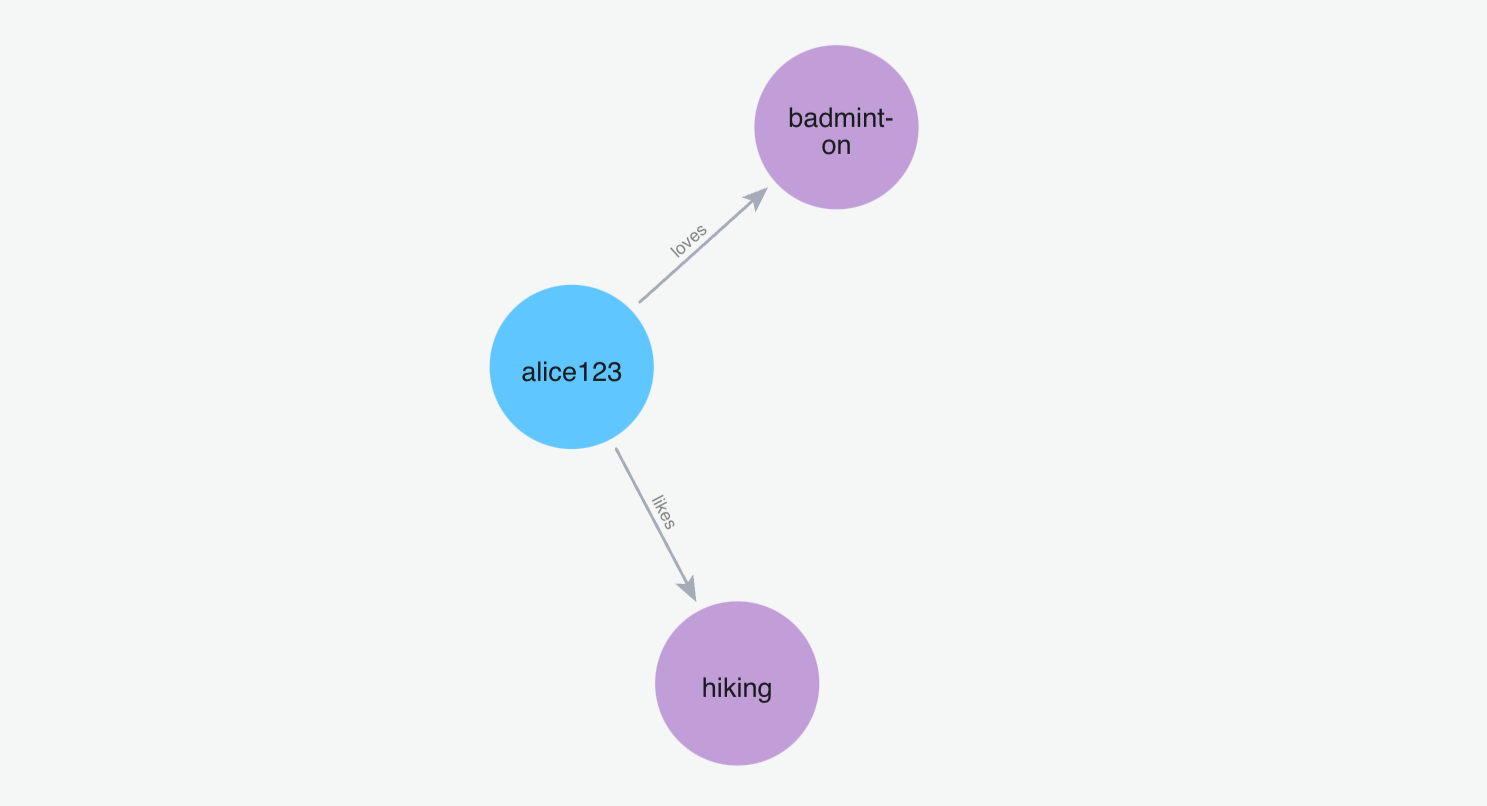
(2)添加记忆"我喜欢打羽毛球"
Python 代码: m.add("I love to play badminton", user_id="alice123")
(3)添加记忆"我讨厌打羽毛球"
Python 代码: m.add("I hate playing badminton", user_id="alice123")
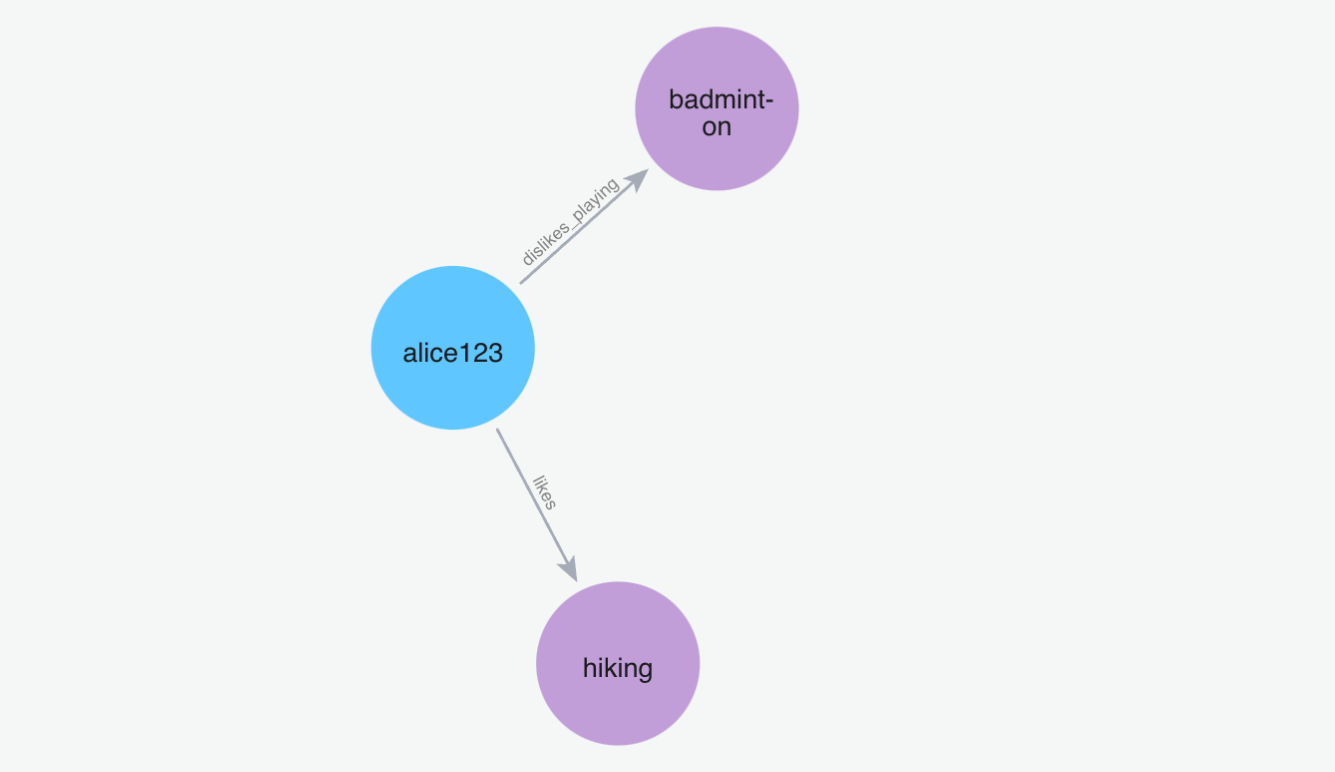
(4)添加记忆"我的朋友叫约翰,约翰有一只名叫汤米的狗"
Python 代码: m.add("My friend name is john and john has a dog named tommy", user_id="alice123")
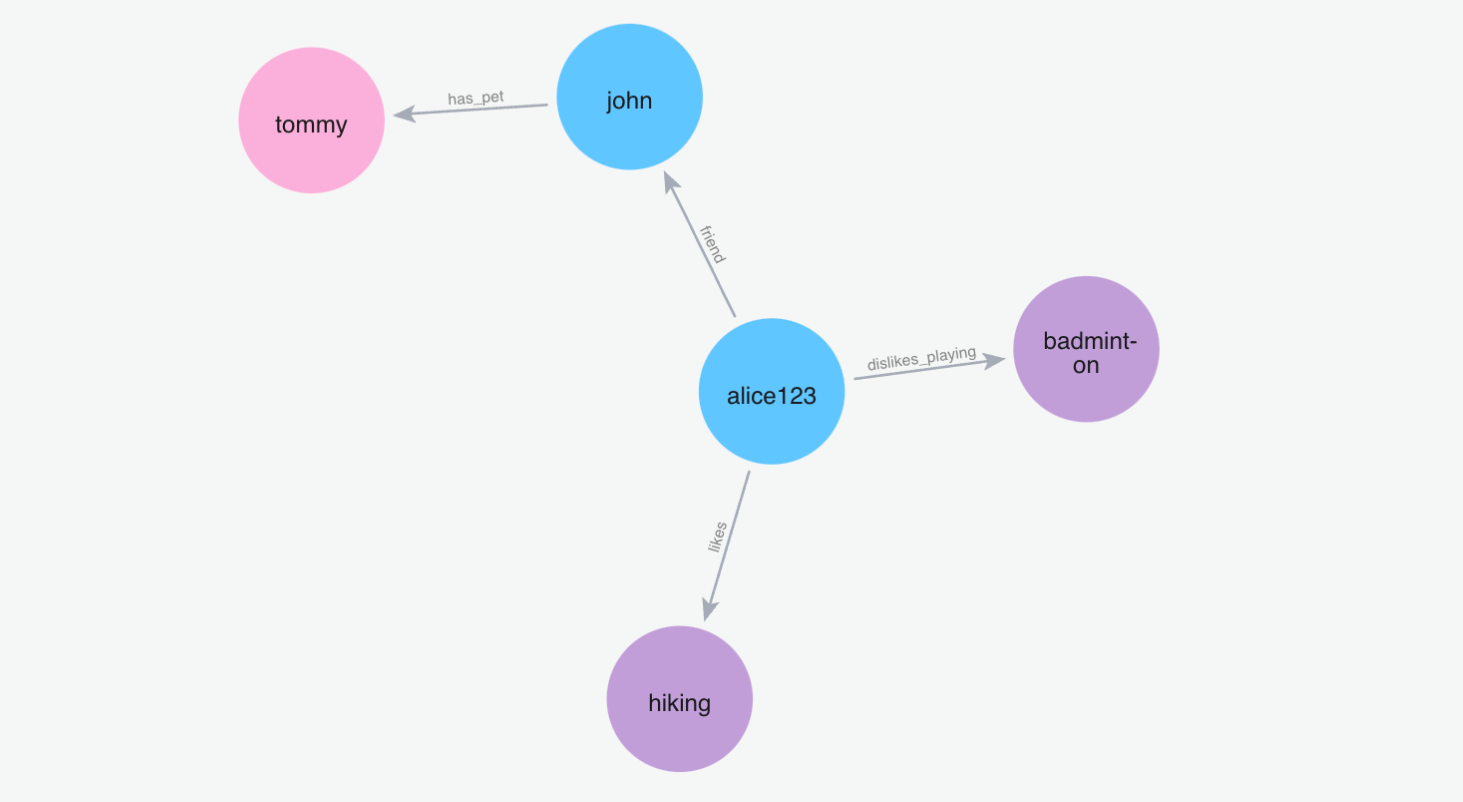
(5)添加记忆"我的名字是爱丽丝"
Python 代码: m.add("My name is Alice", user_id="alice123")
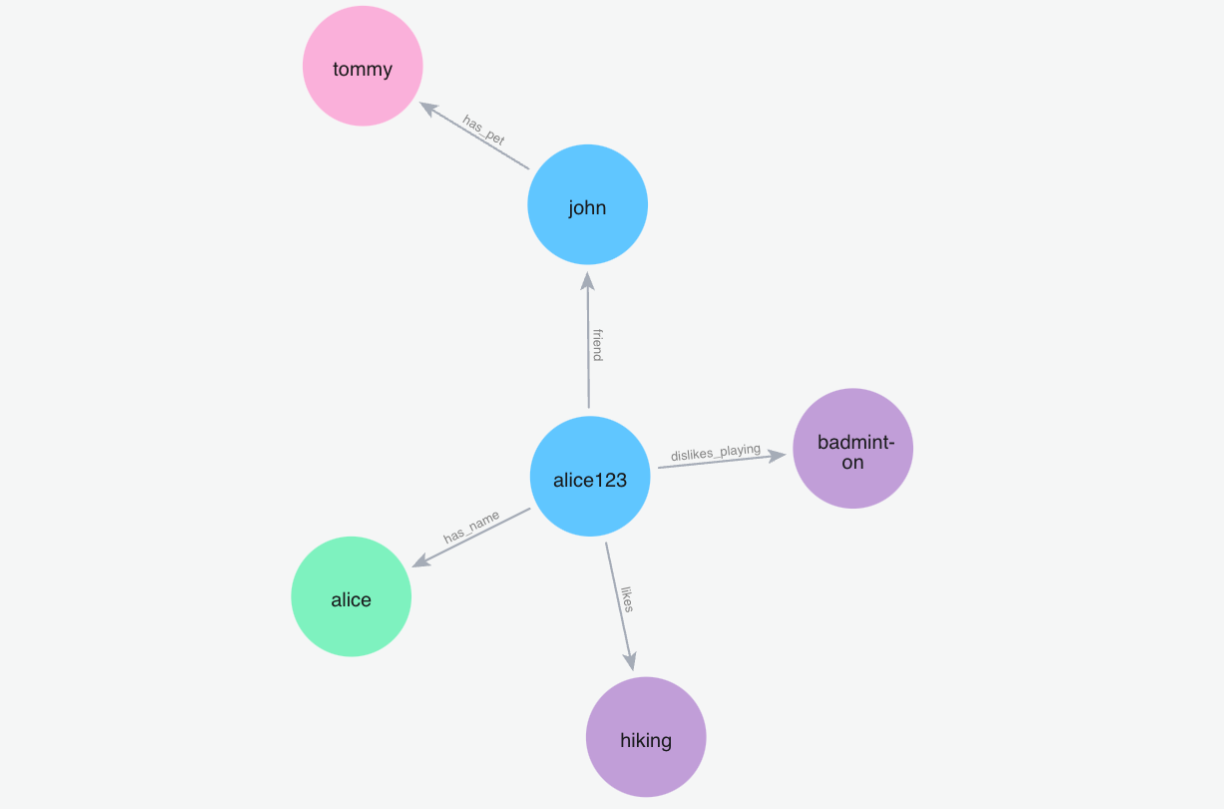
(6)添加记忆"约翰喜欢徒步旅行,哈利也喜欢徒步旅行"
Python 代码: m.add("John loves to hike and Harry loves to hike as well", user_id="alice123")
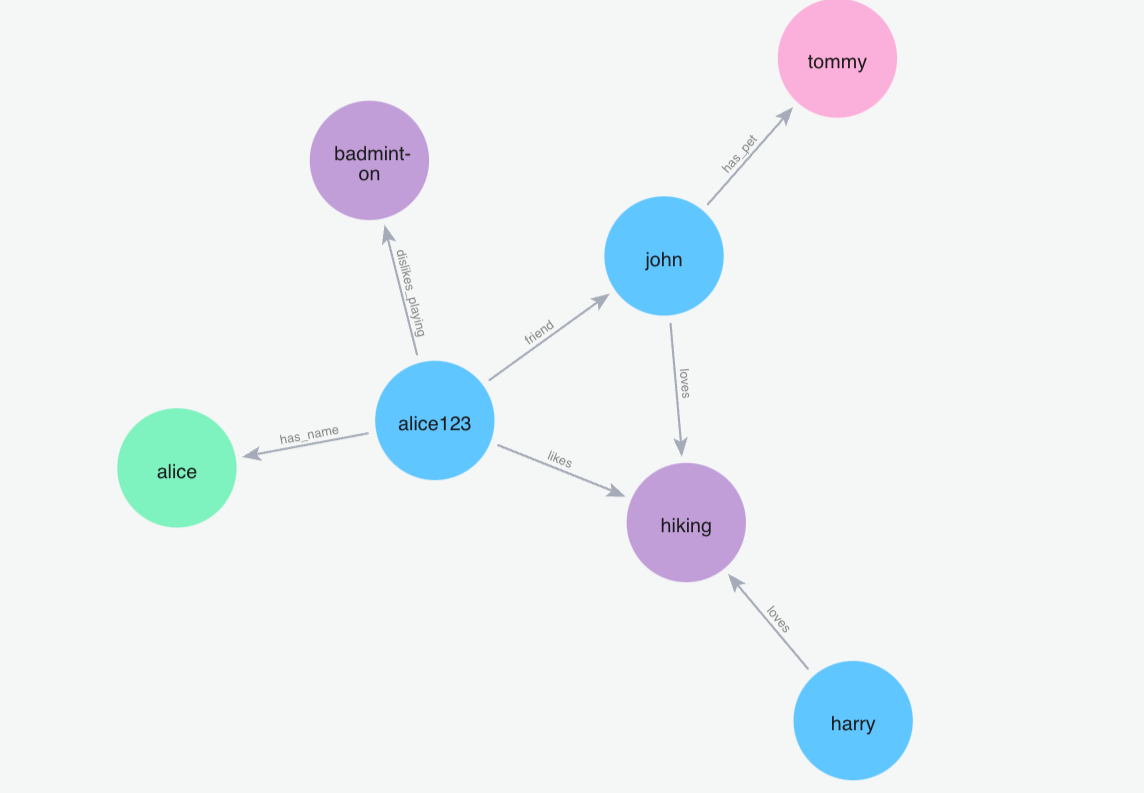
(7)添加记忆"我的朋友彼得是蜘蛛侠"
Python 代码: m.add("My friend peter is the spiderman", user_id="alice123")
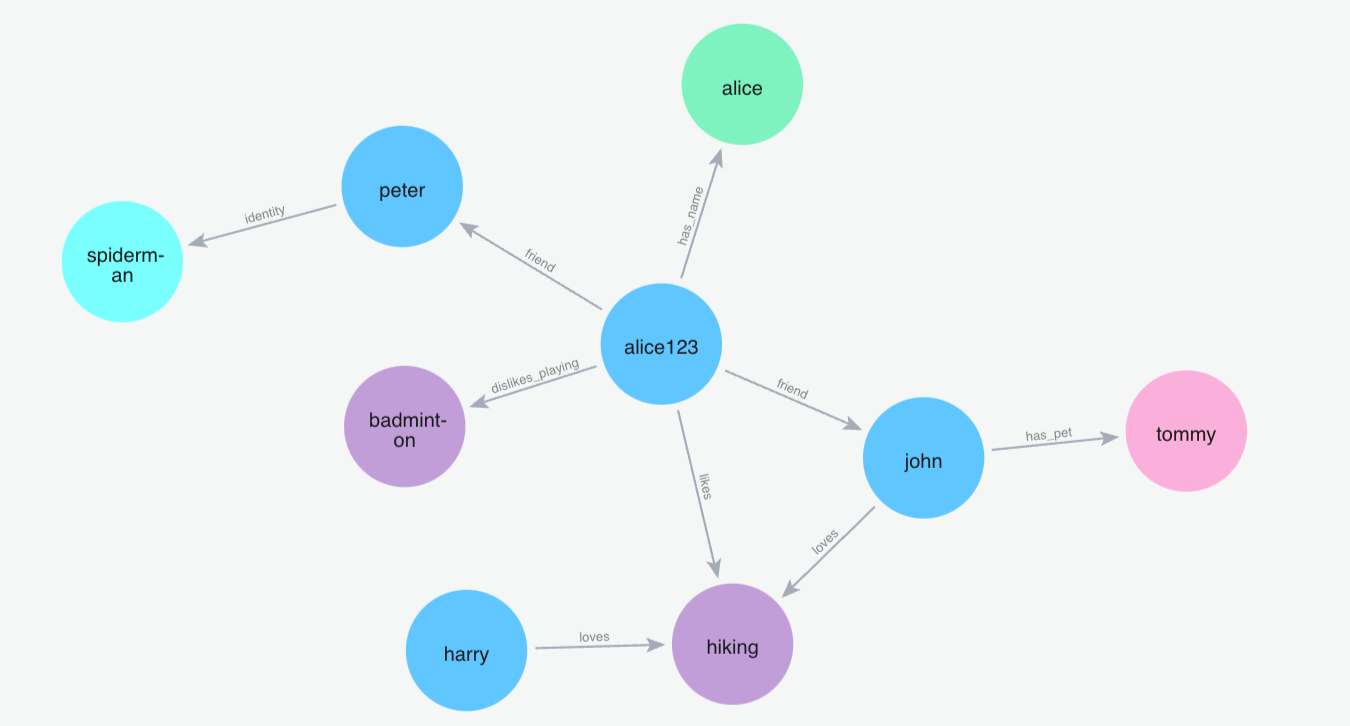
搜索记忆
(1)搜索名字
Python 代码: m.search("What is my name?", user_id="alice123")
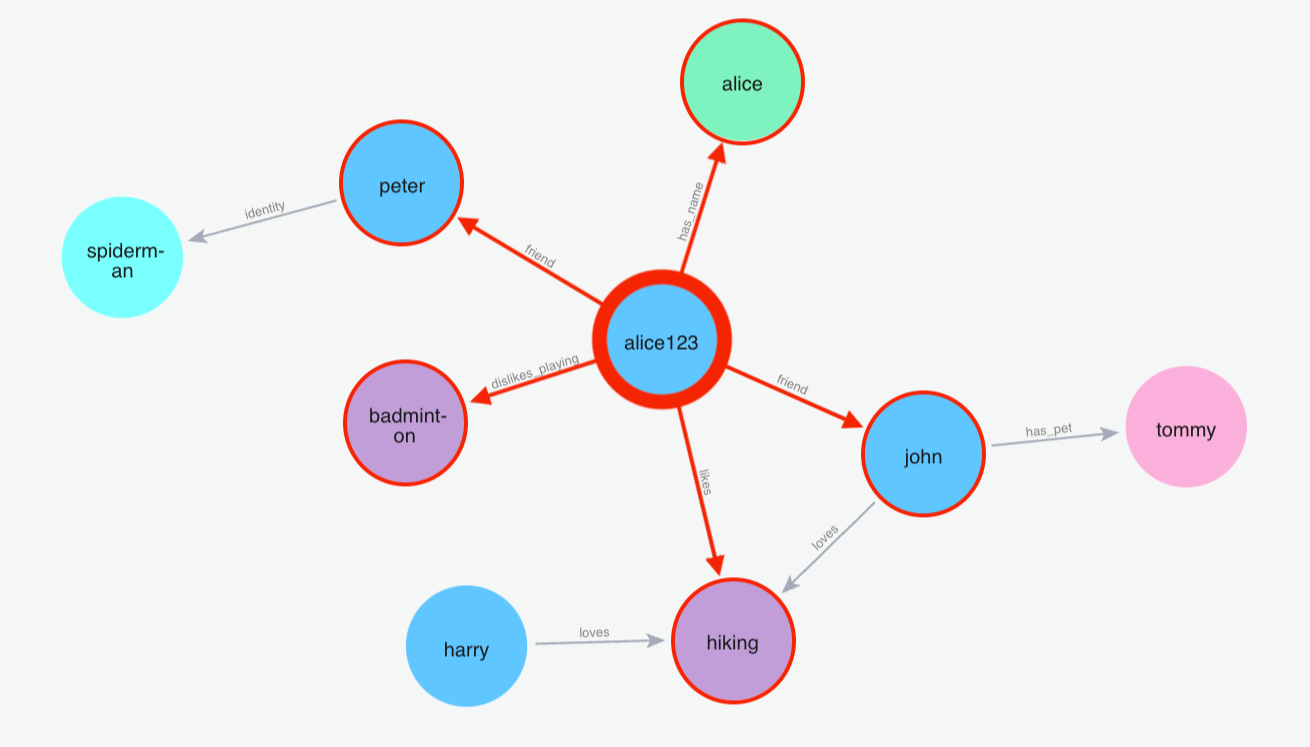
(2)搜索:蜘蛛侠
Python 代码: m.search("Who is spiderman?", user_id="alice123")
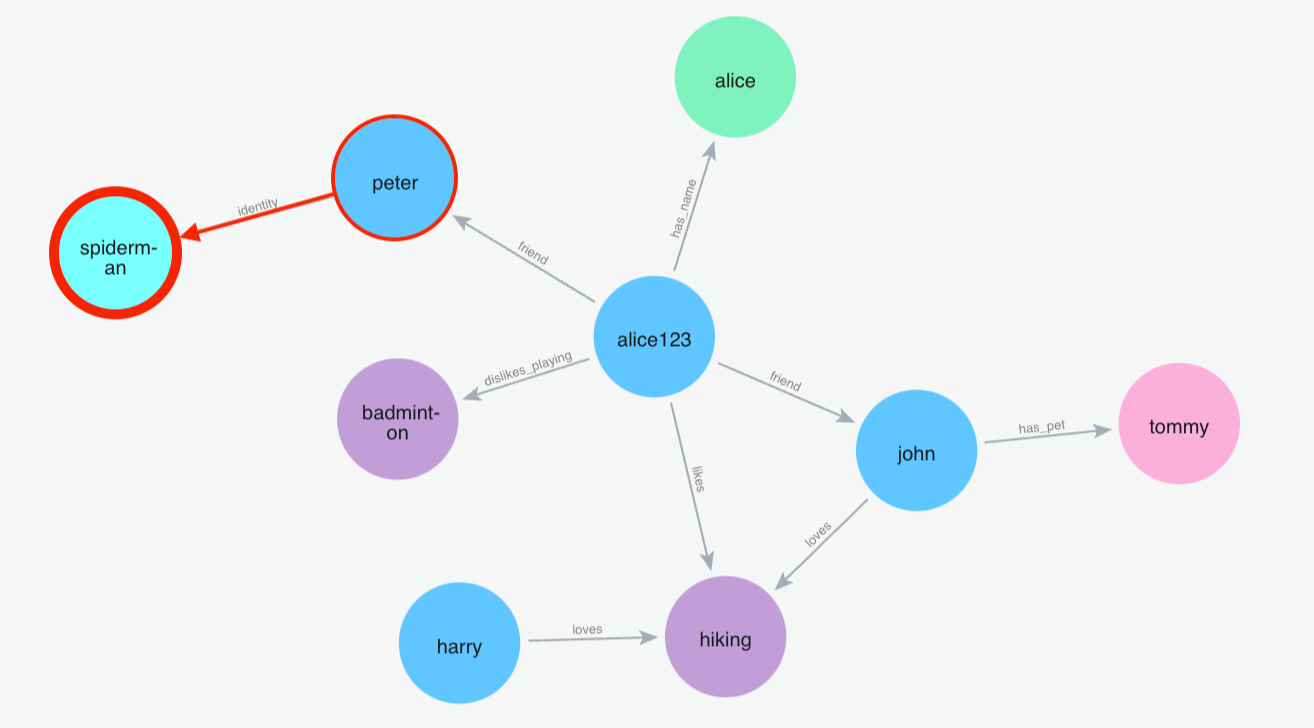
备注:图记忆的实现并非独立,而是与向量存储协同工作。每次添加或检索记忆时,系统会同时操作向量数据库和图数据库,实现信息的多维度管理。
本小节内容来源于 mem0.ai : Example Usage
2.4 OpenMemory MCP
OpenMemory MCP(模型上下文协议)是 Mem0 的核心协议层,旨在为 AI 交互提供本地化的"记忆背包"。MCP 作为统一的记忆基础设施,支持多种 AI 应用(如 Claude Desktop、Cursor、Windsurf 等)通过标准化协议连接,实现跨工具的记忆共享。所有数据均在本地存储,确保用户对数据的绝对隐私和控制权。
MCP 提供了四个核心 API:
add_memories:存储新的记忆对象search_memory:基于相关性和上下文检索记忆list_memories:查看所有存储的记忆delete_all_memories:清除所有记忆
接口示例:
add_memories:存储新的记忆对象POST /add_memories { "memories": [ { "role": "user", "content": "我喜欢科幻电影,尤其是星际穿越。" }, { "role": "assistant", "content": "星际穿越确实是一部经典的科幻电影!我会记住你喜欢这类电影。" } ], "user_id": "alice", "metadata": { "category": "movies" } }search_memory:基于相关性和上下文检索记忆POST /search_memory { "query": "我喜欢什么类型的电影?", "user_id": "alice", "limit": 5 }list_memories:查看所有存储的记忆POST /list_memories { "user_id": "alice" }delete_all_memories:清除所有记忆POST /delete_all_memories { "user_id": "alice" }
OpenMemory MCP 的最大优势在于其完全本地化运行,既保障了用户数据的隐私和安全,又通过标准化协议实现了跨应用的记忆共享和无缝集成。
2.5 原理描述
记忆提取与存储
Mem0 利用 LLM 从对话中自动提取关键信息。该过程包括:
- 分析对话内容,识别重要信息点
- 将信息结构化为可检索的记忆单元
- 为记忆分配相关性标签和类别
- 将记忆存储在向量数据库中
以下是一个简化的记忆提取流程示例:
def extract_and_store_memory(messages, user_id, metadata=None):
# 使用 LLM 提取关键信息
extracted_info = llm.extract_key_information(messages)
# 结构化为记忆单元
memory_unit = {
"content": extracted_info,
"source_messages": messages,
"user_id": user_id,
"timestamp": datetime.now(),
"metadata": metadata or {}
}
# 向量化记忆
vector = embedder.embed(extracted_info)
# 存储在向量数据库中
vector_store.add(vector, memory_unit)
return memory_unit
记忆检索机制
当需要检索记忆时,Mem0 会:
- 将用户查询转换为向量表示
- 在向量空间中搜索相似的记忆
- 根据相关性、时效性和重要性对结果排序
- 返回最相关的记忆供 AI 使用
以下是一个简化的记忆检索流程示例:
def retrieve_memories(query, user_id, limit=5):
# 向量化查询
query_vector = embedder.embed(query)
# 在向量空间中搜索相似记忆
similar_memories = vector_store.search(
query_vector,
filter={"user_id": user_id},
limit=limit
)
# 根据相关性、时效性和重要性排序
ranked_memories = rank_memories(similar_memories)
return ranked_memories
架构组件分析
Mem0 的架构包含以下关键组件:
- LLM 处理器:负责记忆提取和自然语言理解
- 向量存储:用于高效的语义搜索
- 图数据库:用于追踪记忆间的关系
- MCP 服务器:提供标准化 API 接口
- 客户端 SDK:便于开发者集成 Mem0 功能
这些组件协同工作,为 AI 智能体提供完整的记忆管理解决方案。
╔════════════════════════════════════════════════════════════════╗ ║ 候选记忆流程说明 ║ ╠════════════════════════════════════════════════════════════════╣ ║ [1] 用户消息 (User Message) ║ ║ ↓ ║ ║ [2] 解析消息 (Parse Messages) ║ ║ ↓ ║ ║ [3] LLM 抽取事实 (Extract New Facts) ║ ║ ↓ ║ ║ [4] 对每个事实执行向量搜索 (Vector Search) ║ ║ ↓ ║ ║ [5] 获取候选旧记忆 (Retrieve Old Memories) ║ ║ ↓ ║ ║ [6] LLM 决策: ADD / UPDATE / DELETE / NONE ║ ║ ↓ ║ ║ [7] 执行向量数据库操作 (Execute DB Operation) ║ ╚════════════════════════════════════════════════════════════════╝
参考文章:(9 封私信) 解决LLM遗忘问题:Mem0架构深度解析 - 知乎
目前整体可跑通,
待完善部分:
- LLM决策部分:当前存在分组混乱的问题,只会add和update不会delete,例如:
【education】
- 是一个学生 【personal】
- 我是一个老师
- 是一个老师
- 向量化维度低